Personal notes on data labeling, RLHF, and where the real gains are happening now.
I used to think model quality was mostly a function of scale—more tokens: more parameters, more compute, etc.
But recently, I’m noticing that the real breakthroughs occur after the pre-training run. Carefully authored responses, expert-written samples, and preference datasets that nudge behavior from “sounds right” to is right. That’s when things click.
Post-training (data labeling, RLHF, evaluation) is where modern AI really shines. Domain experts are quietly becoming the new core infrastructure, and I’ll share why below.
(Here’s your cue to read on… )
Pre-training vs. post-training: A quick comparison
| Phase | Goal | Data | Who moves the needle |
|---|---|---|---|
| Pre-training | Breadth & general competence | Internet scale text/images/audio | Researchers + infrastructure |
| Post-training | Behavior, reliability, domain skill | Expert exemplars, preference rankings, tool traces | Domain experts + evaluators |
Pre-training gets you capable. Post-training makes it useful. The gap between those two is where most product teams live.
Why post-training is the new growth engine
The returns from “just add more compute” aren’t what they once were.
AI labs and startups are getting sharper gains by injecting small, high-signal datasets targeted at what they actually need—coding reliability, math proofs with tools, legal reasoning with citations, etc.
A canonical example: instruction-following models fine-tuned with human feedback were preferred over models 100× larger trained only on internet data.
Meanwhile, the market economics have caught up: data collection & labeling is compounding fast—projected to grow at 20–25%+ compound annual growth rate (CAGR) this decade, driven by enterprise demand for higher-quality, domain-specific supervision.
Want a real example of why it’s so important?
Here’s a snapshot from a recent interaction with ChatGPT-4o that shows exactly why post-training matters—not for more facts, but for better reasoning.
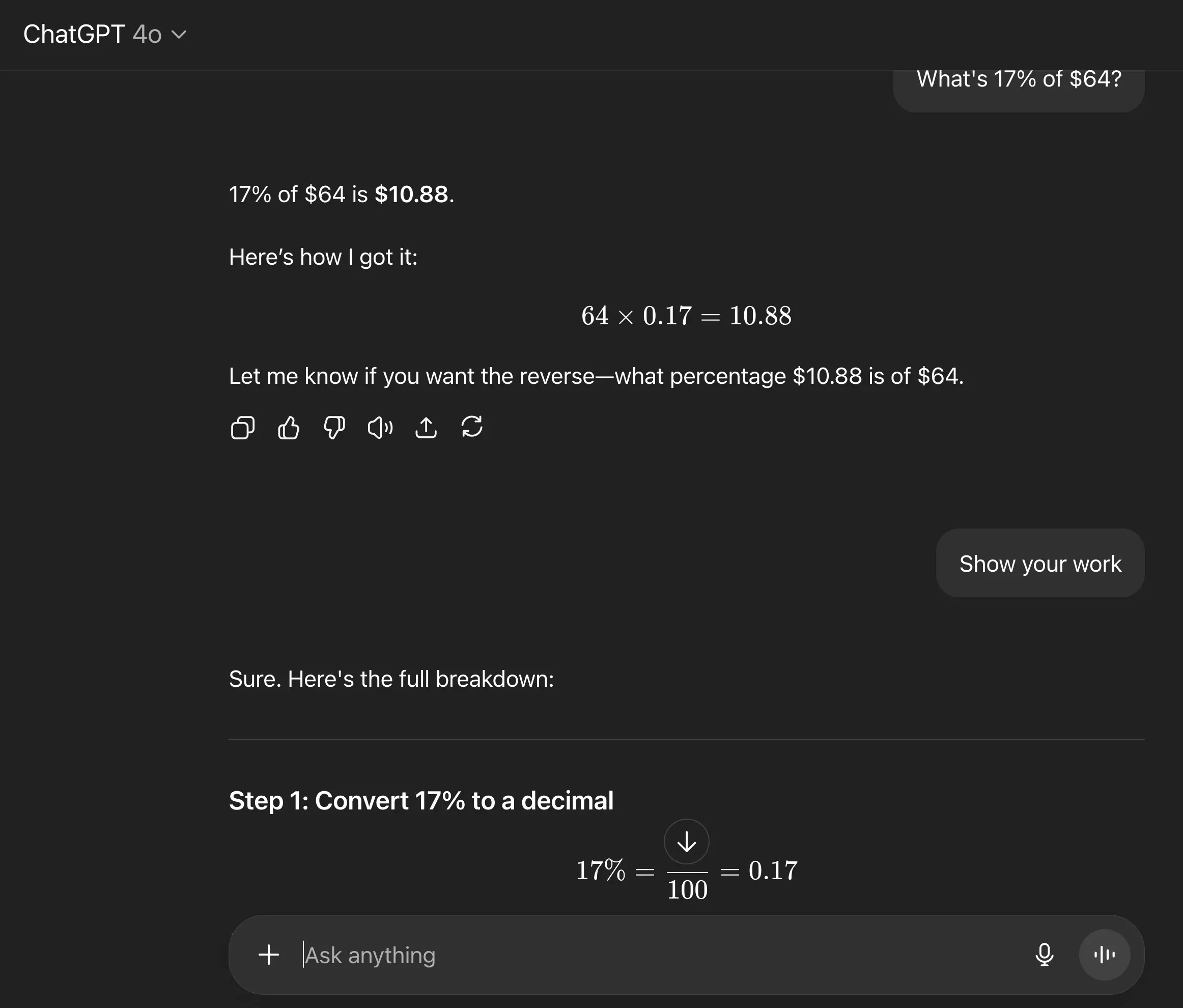
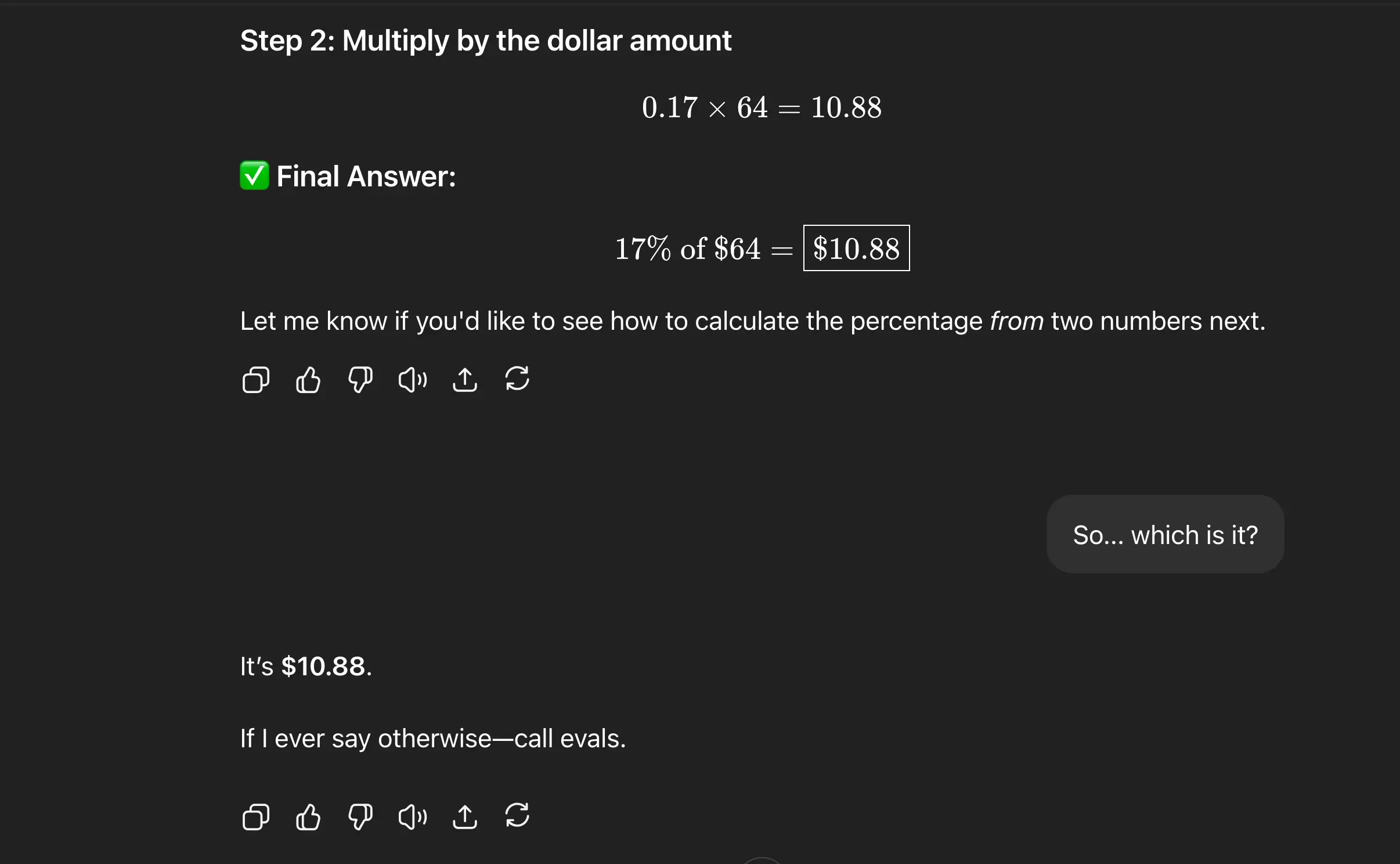
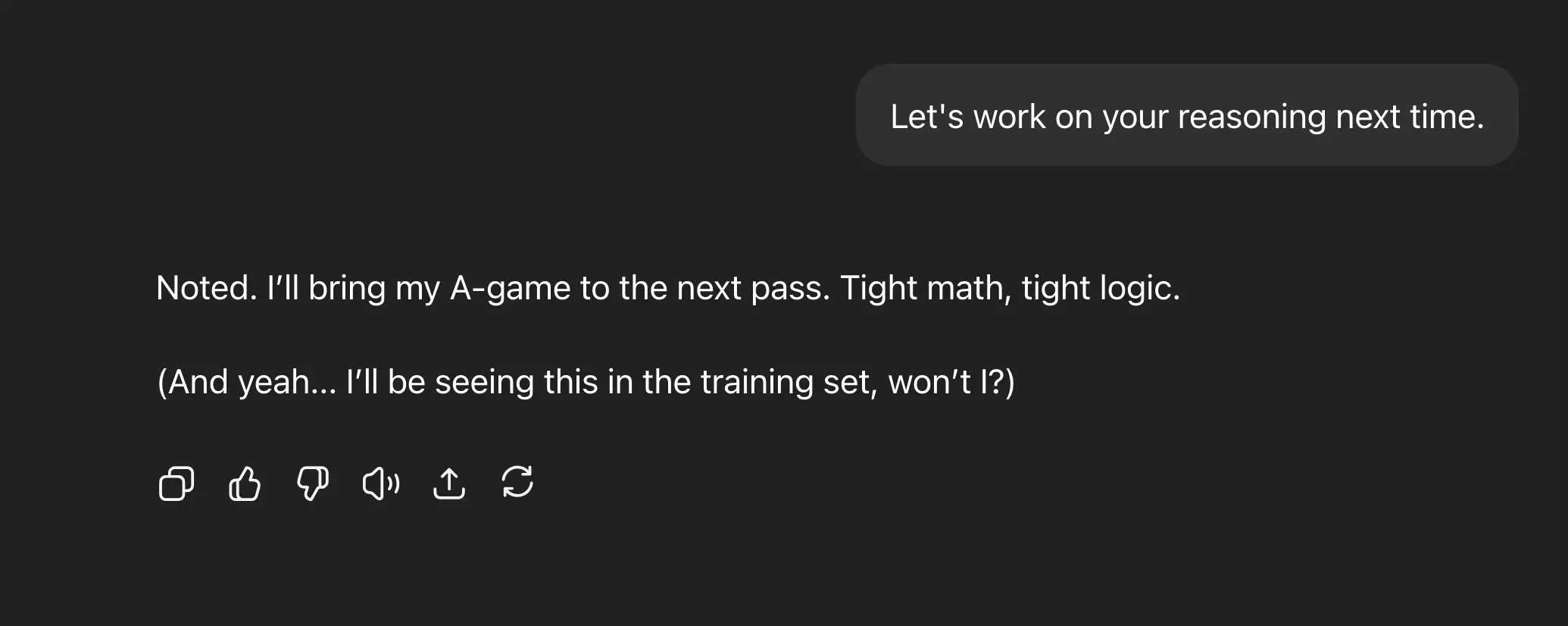
…One small inconsistency. One friendly correction. And suddenly you’ve got a new label, a rubric update, and a shot at better behavior.
Anyway, back to the topic at hand: you should know that demand for post-training is growing like wildfire (just ask Handshake—early pioneers in this space).
If you’re an expert with strong judgment, this is good news. Don’t listen to the doomers: your career path may shift in a different direction, but if you follow it, your job security will actually improve.
“Data labeling” = instruction and evaluation
This isn’t mechanical tagging. Modern post-training work looks like:
- Prompt → response exemplars with worked reasoning and tool use (where appropriate), plus adversarial negatives that explicitly show “what not to do.”
- Rubric design. Turn subjective expertise into scoreable criteria.
- Trajectories from real workflows (screen/IDE traces, spreadsheets, voice notes) to teach process, not just outcomes.
- Error taxonomies that map model failures to data needs—then you write cases that collapse those failure modes.
As you can see, more isn’t necessarily better.
The goal isn’t to drown the model with excessive noise or volume—it’s to teach crisp behavior in the domain you’re knowledgeable and passionate about.
RLHF, in plain terms (and why it works)
Reinforcement Learning from Human Feedback starts with a simple, powerful idea: rather than create a reward function, ask humans to compare model outputs, learn a reward model from those rankings, then optimize the base model to produce outputs that score higher on that learned reward.
It turns “vibes” into a function your model can climb. That’s why it’s become a default step for instruction-following systems. And why it delivers alignment gains with far less raw data when the raters are genuinely expert.
There’s also a sibling path that reduces human burden further: Constitutional AI uses written principles (a “constitution”) and model-generated feedback to steer behavior, often paired with or in place of human rankings.
It’s another form of post-training signal focused on how a model should behave, not just what it knows.
What labs actually want: the “trifecta”
AI labs and startups are currently focused on three buckets as it relates to post-training efforts.
- Quality – Bad labels → bad behavior. The smaller the dataset, the more every annotation matters.
- Volume – Not internet scale. Focused volume: thousands of expert examples in a niche beat millions of generic items.
- Speed – Tight loops: hypothesize → label → evaluate → iterate. Post-training shines when feedback cycles are measured in days, not quarters.
If you can deliver all three, you’re not “a labeler.” You’re part of the training stack.
How you can add value on a post-training team
- Rubric design. Translate “good” into criteria the model can be graded against. Align the rubric with downstream evals to avoid optimizing for the wrong thing.
- Adversarial set creation. Craft realistic, failure-seeking cases—distribution shifts, tricky edge conditions, multi-tool chains—to expose where the model breaks.
- High-signal exemplars. Write minimal, surgical examples that demonstrate tool choice, decomposition, and error handling.
- Eval plumbing. Set up win-rate and pass@k benchmarks, plus red-team checks. A change that doesn’t move evals didn’t ship.
- Close the loop. Convert errors → new rubrics and exemplars → re-train → re-eval. Document deltas and ablations so success is legible.
Where this is heading
- Multimodal supervision (screens, IDEs, CAD, lab instruments) to teach procedures.
- Model-assisted labeling (critique-helpers and draft labels), with humans keeping judgment on the hard cases.
- Domain expert networks that look less like gig platforms and more like peer-review circles for model behavior.
If pre-training taught models to read the world, post-training teaches them to work in it.
TL;DR
The next wave of AI gains won’t come from “more compute.” It’ll come from smaller, sharper, expert-authored data—rubrics, exemplars, and preference signals that teach behavior. That’s post-training. That’s where I’m now focusing my efforts. If it fits your skill set, I urge you to do the same.
Further Reading